Sifting through high-volume applicant pools, you know glossy résumés and practiced interview answers reveal only part of the picture. To hire with confidence, you need fast, objective evidence that a candidate can absorb new information quickly and translate it into on-the-job results. A rigorously designed custom aptitude test provides that proof.
Aptitude testing comes in two broad flavors, each serving a different strategic need. General Mental Ability (GMA) gauges broad reasoning, problem-solving, and overall learning agility. Because it captures how quickly a person absorbs and applies new information, GMA is usually ideal for graduate programs, internships, and any early-career or rotational role where potential matters more than track record and the organization plans to invest in rapid development.
By contrast, domain-specific aptitude tests focus on narrower skill sets, such as numerical reasoning for finance analysts, spatial visualization for engineers, coding speed drills for junior developers, and so on. These targeted assessments shine when you’re screening for specialist roles, selecting employees for promotion tracks, or validating that upskilling initiatives have actually taken hold.
Timing is everything. Research shows that learning agility peaks within the first decade of a career; catch high-potential talent during this window and you slash the odds of costly mis-hires while boosting long-term retention. In short, deploy GMA tests to identify raw horsepower early, and add domain-specific measures when the role or the next career step requires focused expertise.
Start at the source: schedule listening sessions with your subject-matter experts and mine data-rich resources like O*NET to capture the core knowledge, skills, and abilities the role truly demands. Next, translate those raw knowledge, skills, and abilities into competencies that support your team’s strategic goals. Think of it as connecting shop-floor tasks to outcomes at the boardroom level.
Example: for a data analyst role, subject-matter experts might list SQL querying, data-cleaning discipline, and pattern-spotting savvy as critical KSAs. You’d map those to broader competencies such as analytical reasoning (supports strategic forecasting), data accuracy (protects decision quality), and information synthesis (fuels stakeholder dashboards). With that foundation in place, create a concise blueprint of three to six aptitude dimensions, such as logical reasoning, data accuracy, and verbal insight, for each position. This blueprint becomes the DNA for every item you write and every score report you ultimately deliver.
First, lock in the core writing standards. Aim to keep every stem at a sixth to eighth grade reading level, unless the role truly requires higher level vocabulary, so most candidates aren’t tripped up by language. Limit each item to a single mental operation, such as solving for X, choosing the next step, or interpreting a chart, because combining multiple cognitive demands can obscure what you're actually measuring. And steer clear of regional slang or cultural references; nothing tanks fairness faster than an idiom only half your talent pool recognizes.
Next, build composite “content-group” items. Present one mini scenario, such as a data table, short passage, or workflow diagram, and follow it with three to five linked questions. This deepens construct coverage while letting you set question-level timers that preserve the speed element essential to learning-agility measures. Candidates stay focused; item theft gets harder.
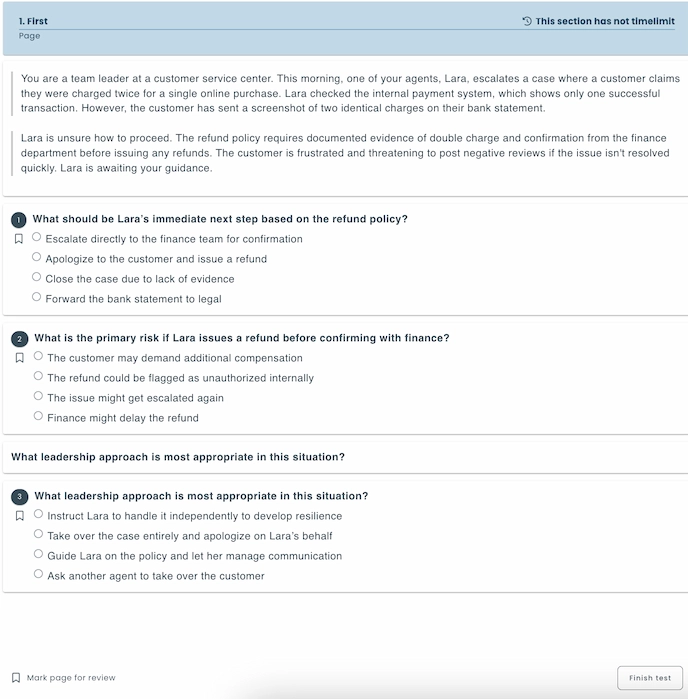
Mix up your response modes to capture different flavors of reasoning without bloating test length. Multiple-choice remains the workhorse, but sprinkle in numeric input for calculations, short text input for concise explanations, image hotspots for visual logic, and the occasional attention-check item to flag random clickers. Variety keeps engagement high and makes it tougher for bots to game the system.
Leverage AI assisted item generation to scale quickly, but do it with guardrails. Feed your language model a strict schema, including blueprint tag, difficulty target, and cognitive level, so it produces true parallel forms instead of random lookalikes. Then apply systematic randomization at delivery so no two candidates see the same combination. Finally, run every new item through an AI-answerability sweep; if a public model can nail it in milliseconds, rewrite or retire the question.
A quick rule of thumb: aim for four to five solid items per aptitude dimension. That sweet spot balances measurement reliability with test length, giving you sub-scores sturdy enough to guide hiring decisions without exhausting your candidates.
Before you roll out an aptitude test to real candidates, run a pilot first. Gather responses from at least 100 people, as that is the critical mass needed for stable classical item statistics. If you want extra confidence in your numbers or plan to compare scores across multiple forms later, push the sample closer to 300; larger datasets sharpen your estimates and make bias checks more reliable.
Once the data is in, zero in on three headline metrics. Item difficulty (p value) should sit between .25 and .85. That sweet spot keeps you from wasting space on questions everyone gets right or almost no one gets right.
Item discrimination (point-biserial r-pbis) needs to clear .25; lower values mean an item isn’t separating high- and low-ability test-takers and likely needs a rewrite.
Finally, look at distractor efficiency, in a multiple-choice question, every wrong option (“distractor”) should look credible enough to tempt someone who doesn’t truly know the answer. To verify that your distractors are doing their job, focus on the subset of test-takers who answered the item incorrectly. Check how their wrong choices are distributed:
Target benchmark: at least 60% of those incorrect responses should be spread across your intended distractors, rather than everyone avoiding them and guessing the same obvious trap, or worse, leaving them untouched.
Why it matters: if one distractor attracts almost all the wrong answers while the others are rarely chosen, the unused options are basically signposts saying “this can’t be right,” which makes the item easier than you intend and weakens its discrimination power.
Example: Suppose 200 people attempt an item and 80 get it wrong. You want about 48 (60% of 80) of those wrong responses to be divided among the incorrect options you wrote. If only 5 people pick Distractor C and none pick Distractor D, those two need revising. Rewrite or replace them so they look equally plausible.When each distractor pulls its weight, the item becomes more informative and fair because it differentiates between true mastery and lucky guessing.
After piloting, convert raw scores into a scale that hiring managers can interpret at a glance. For most small-to-mid-sized testing programs, Classical Test Theory (CTT) scaling does the job: you transform raw totals into a 0-to-100 or similar band and publish performance descriptors (e.g., Basic, Proficient, Advanced).
When you release an updated test form, for example if you’ve refreshed 20 percent of the items for security, you need to make sure scores from the new version line up with the old. The simplest way is a mean-sigma equate: administer both forms to a small anchor group, then adjust the new raw scores so they share the same mean and standard deviation as the reference form. This keeps “75” on Form B meaning what “75” meant on Form A, preserving fairness and year-over-year comparability without adding statistical overhead you don’t need.
Once your items are scaled and equated, make sure the test scores are consistent enough to trust. Start with Cronbach’s alpha, the standard index of internal consistency. For any hire/no-hire decision, aim for an alpha of 0.80 or higher; that tells you the items are working together to measure a single underlying construct rather than a noisy grab-bag of skills.
Next, translate that reliability into something managers can feel: the Standard Error of Measurement (SEM). SEM tells you how much a candidate’s observed score might wobble if they took equally good parallel forms.
Keep that error band tight, no larger than one quarter of a standard deviation (less than or equal to 0.25 SD). In practice, if your scaled scores have an SD of 10, a SEM of 2.5 or less means you can draw confident cut-lines and performance bands without second-guessing whether a pass is really a pass.
To demonstrate the validity of the test, we gathered evidence on four fronts. Content validity was established through ratings by subject-matter experts who judged every item for relevance and clarity.
Construct validity was examined with exploratory or confirmatory factor analysis (EFA/CFA); items loading at 0.30 or higher confirmed that each factor measured a distinct ability.
Criterion-related validity was shown by correlations of at least r = 0.30 between test scores and practical outcomes such as job or training performance, indicating meaningful predictive power.
Lastly, to make sure the test treats everyone equally, we ran a Differential Item Functioning (DIF) analysis with the Mantel-Haenszel method. This produces a ΔMH value for each question, showing whether it is easier or harder for one demographic group once overall ability is held constant. We required every item’s absolute ΔMH to stay below 1.0, a standard cutoff for “negligible” DIF, so no subgroup gained a real advantage or suffered a disadvantage.
Choose the standard that fits your program size and data reality. Angoff is the workhorse for pass or fail aptitude tests, whether you use a single fixed form or systematically randomized item families. SMEs estimate how many minimally qualified candidates should answer each question correctly, and you average those ratings into a defensible cut-score.
Bookmark only earns its keep when you already have every item calibrated on the same IRT scale; SMEs “flag” the transition point on an ordered map, and that ability level becomes the cut. Finally, Contrasting-Groups shines when you have hard performance labels (competent vs. not-yet-competent): plot the two score curves and set the decision line where they intersect to minimise false passes and false fails.
Build a fixed form of roughly 25–30 items that candidates can finish in about 30 minutes. Keep speed pressure consistent and, if you use systematic randomization, shuffle equivalent items so no two people see the same mix.
If you later migrate to a calibrated bank, a short adaptive option (approximately 20 items in 15 to 20 minutes) can trim testing time while maintaining precision, as long as you control exposure with a Sympson Hetter or similar algorithm.
Layer your defences. Start with AI video proctoring that tracks gaze direction, detects secondary faces, and listens for suspicious background chatter, all in real time. For higher-stakes sittings, bolt on an optional lockdown-browser shell that disables screen-sharing, copy-paste, and tab-switching.
Strengthen identity assurance with photo ID checks at login and periodic face-match prompts mid-exam. Finally, refresh about 20 % of the item pool every quarter and monitor response-time analytics for patterns that suggest answer-sharing or automated tools. Together, these measures make your assessment far harder to game while keeping the candidate experience smooth.
Treat your technical manual as the single source of truth for anyone who needs to inspect or improve your test. It should open with the purpose of the assessment and the audience it serves, then lay out the competency blueprint that links every item to a specific KSA. Follow with full item statistics from the pilot (difficulty, discrimination, distractor efficiency) and the resulting reliability indices and validity evidence.
Detail the cut score rationale, including the method used, SME panel makeup, and final pass mark, so decision makers can see exactly how “qualified” was defined. Round things out with a summary of security protocols (proctoring layers, item-refresh cadence) and a set of sample score reports illustrating how results are communicated to hiring managers and candidates. Keep the manual up to date as you refresh items or policies; it’s both your continuous-improvement playbook and your best defense if auditors or legal teams come knocking.
Accurate reporting turns assessment data into actionable hiring intelligence. At a minimum, recruiters need three layers of feedback:
TestInvite’s built-in reporting covers these needs out of the box. When a candidate finishes, the platform assigns score bands and attaches plain-language notes to each dimension, so hiring managers never have to interpret raw numbers. You can even customize each dimension’s name, description, and weighting in the Dimension Settings, aligning every report with your role profiles.
Behind the scenes, the Export Manager empowers test administrators to pull down comprehensive datasets, including dimension level scores, overall score distributions, detailed activity logs, and any flagged integrity events such as suspicious answer patterns or proctoring alerts, in CSV or JSON format for deeper analysis. And when you need a quick visual, an interactive spider chart overlays individual results on the role blueprint and can be shared instantly via secure link, with no spreadsheet gymnastics required.
With TestInvite, you can either upload your own items by applying the design principles you’ve just read, or draw directly from the platform’s ready made aptitude tests in the Talent Library. Whichever route you choose, TestInvite handles the heavy lifting: automated scoring, fairness analytics, branded reports, and secure delivery. Solid psychometrics plus TestInvite’s infrastructure turn hiring decisions from educated guesses into evidence based calls, while still leaving room for human judgment. Happy testing!
For a traditional fixed form, keep the total seat time between 25 and 40 minutes. This is long enough to cover multiple dimensions but short enough to avoid fatigue. If you’re running a calibrated computer-adaptive test, you can usually trim that to about 15–20 minutes while maintaining accuracy.
It can, unless you mitigate the risk. Offer practice items so all candidates know what to expect, monitor Differential Item Functioning (DIF) stats to catch timing-related bias, and lengthen or remove per-item timers if certain subgroups consistently fall behind.
Not automatically. Adaptive delivery pays off only when you have a bank of at least 300 well-calibrated items and the server capacity to serve them dynamically. Otherwise, a well-designed fixed form with systematic randomization will perform just as reliably.
Rotate or revise roughly 20 percent of the item pool every quarter, or sooner if any single item reaches about 10 percent exposure among test takers, to stay ahead of content sharing and memory effects.
Rely on large, secure item pools, embed questions in rich job-context scenarios that are hard to solve through simple lookup, and deploy real-time anomaly detection to flag answer patterns that match known AI response signatures.
