Automated essay scoring (AES) is the process of using artificial intelligence to evaluate essays according to predefined scoring dimensions. AES systems assess factors such as idea development, organization, coherence, task relevance, and language quality. The field has evolved from n-gram and feature-based techniques to transformer-based Large Language Models (LLMs), which can apply rubrics directly and generate reliable, consistent scores without dedicated model training.
Automated essay scoring refers to the use of artificial intelligence to evaluate essays by analyzing dimensions such as content, structure, and overall writing quality, and then assigning a score that is consistent with human evaluations.
AES systems don’t just check spelling or grammar. They assess essays across multiple dimensions of writing quality, such as organization, coherence, idea development, style, and adherence to the prompt.
Modern automated essay scoring systems lets you decide which aspects of writing the system should evaluate, and it scores accordingly.
Early automated essay scoring systems were built on data-trained models. Starting in the 1960s with projects like Project Essay Grade (PEG), AES relied heavily on large sets of human-scored essays to train statistical algorithms. These systems learned patterns by correlating surface level properties such as sentence length, vocabulary usage, and grammatical markers with scores assigned by expert graders.
Throughout the 1990s and 2000s, AES evolved into more sophisticated machine learning models, but the core dependency remained the same. The system could only score accurately after being trained on substantial amounts of labeled essay data. This “train-then-score” paradigm defined the early generations of AES technology.
Modern automated essay scoring systems powered by large language models-have shifted from training-dependent workflows to instruction-based scoring. Instead of requiring hundreds of human-graded essays to train a custom model, today’s AI can score writing by following explicit evaluation criteria, such as rubrics and task-specific instructions.
This allows organizations to score essays using flexible, customizable prompts without building or training a model.
Put simply:
You tell the AI what to evaluate, and it evaluates it. Then, assigns a score and provides feedback for both candidate and the test admin.
As a result, modern AES solutions deliver faster setup and broader adaptability while eliminating the data-collection and training burdens of earlier systems.
The exact criteria depend on what you instruct the AI to evaluate, but most AES models typically measure the following core aspects of essay quality:
Relevance to the prompt
Depth of explanation, analysis, or argumentation
Accuracy of information
Evidence, examples, and reasoning
Logical flow of ideas
Clear paragraph structure
Effective transitions
Overall essay cohesion
Vocabulary richness and precision
Sentence variety
Tone and clarity
Control of academic or formal language (when expected)
Grammar and syntax
Spelling and punctuation
Proper sentence boundaries
Correct usage and mechanics
Introduction, body, and conclusion structure
Alignment with expected essay format (e.g., argumentative, analytical)
Lexical diversity
Semantic similarity to prompt
Readability metrics
Cohesion and discourse markers
LLM-based automated essay scoring systems use advanced transformer models such as ChatGPT (OpenAI), Gemini (Google DeepMind), and Claude (Anthropic) to evaluate essays in a way that closely resembles human reasoning.
1. You provide the question and the evaluation criteria
The system receives the essay prompt and the scoring rubric.
2. The AI reads and interprets all inputs
The LLM processes the prompt, the rubric, and the student’s response together. It understands what the task requires and which dimensions must be evaluated.
3. The AI evaluates the response according to the criteria
Because LLMs can follow natural-language instructions, the model evaluates the essay directly based on the rubric. It assesses aspects such as relevance, organization, coherence, argument strength, language use, and overall writing quality, depending on what the rubric specifies.
4. The system generates a score
The LLM aligns the essay with the rubric descriptors and assigns a score that reflects how well the response meets each criterion.
5. The AI produces feedback
The system can generate:
candidate-facing feedback (strengths and weaknesses)
administrator-facing feedback (a justification explaining why the score was assigned)
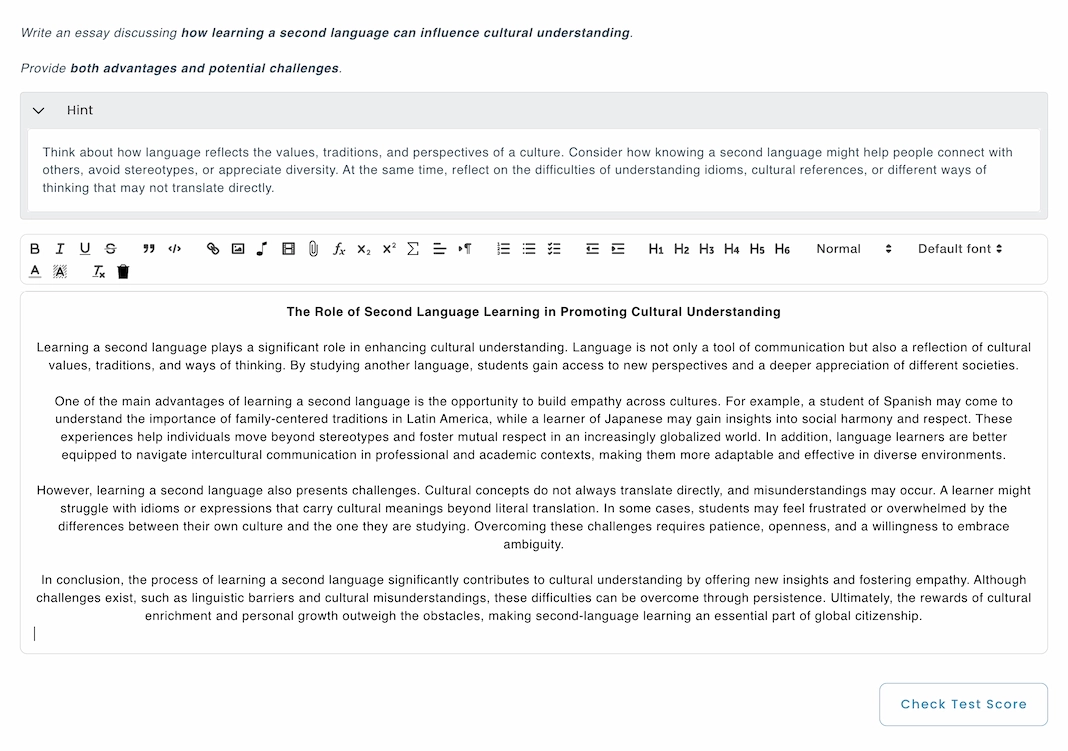
Context:
The test taker is a college student majoring in Languages. The essay should demonstrate academic writing skills, rich vocabulary, and clear argumentation.
Evaluation criteria:
1. Content & Relevance (40%)
Addresses the topic directly.
Includes both advantages and challenges.
Uses relevant examples.
2. Structure & Organization (20%)
Clear introduction, body, and conclusion.
Logical flow of ideas with transitions.
3. Language & Vocabulary (40%)
Grammar accuracy, spelling, and sentence structure.
Academic tone, rich vocabulary, and fluency.
TestInvite’s AI scoring system uses large language models to evaluate essays according to the scoring criteria defined by the test creator. Instead of relying on pre-trained, fixed scoring models, the system grades each response by interpreting the question, understanding the candidate’s answer, and applying the rubric directly.
Because the LLM follows explicit evaluation instructions, organizations can design fully customized evaluation instructiond and receive fast, standardized scoring across large volumes of responses.
In addition to numerical scoring, the system also generates qualitative feedback. It provides candidates with constructive strengths-and-weaknesses feedback to support learning, while offering administrators a separate, rubric-based explanation that clearly justifies why each score was assigned.
[1] Pei Yee Liew and Ian K. T. Tan. 2025. On Automated Essay Grading using Large Language Models. In Proceedings of the 2024 8th International Conference on Computer Science and Artificial Intelligence (CSAI '24). Association for Computing Machinery, New York, NY, USA, 204–211. https://doi.org/10.1145/3709026.3709030
